fastapi处理请求的整个流程
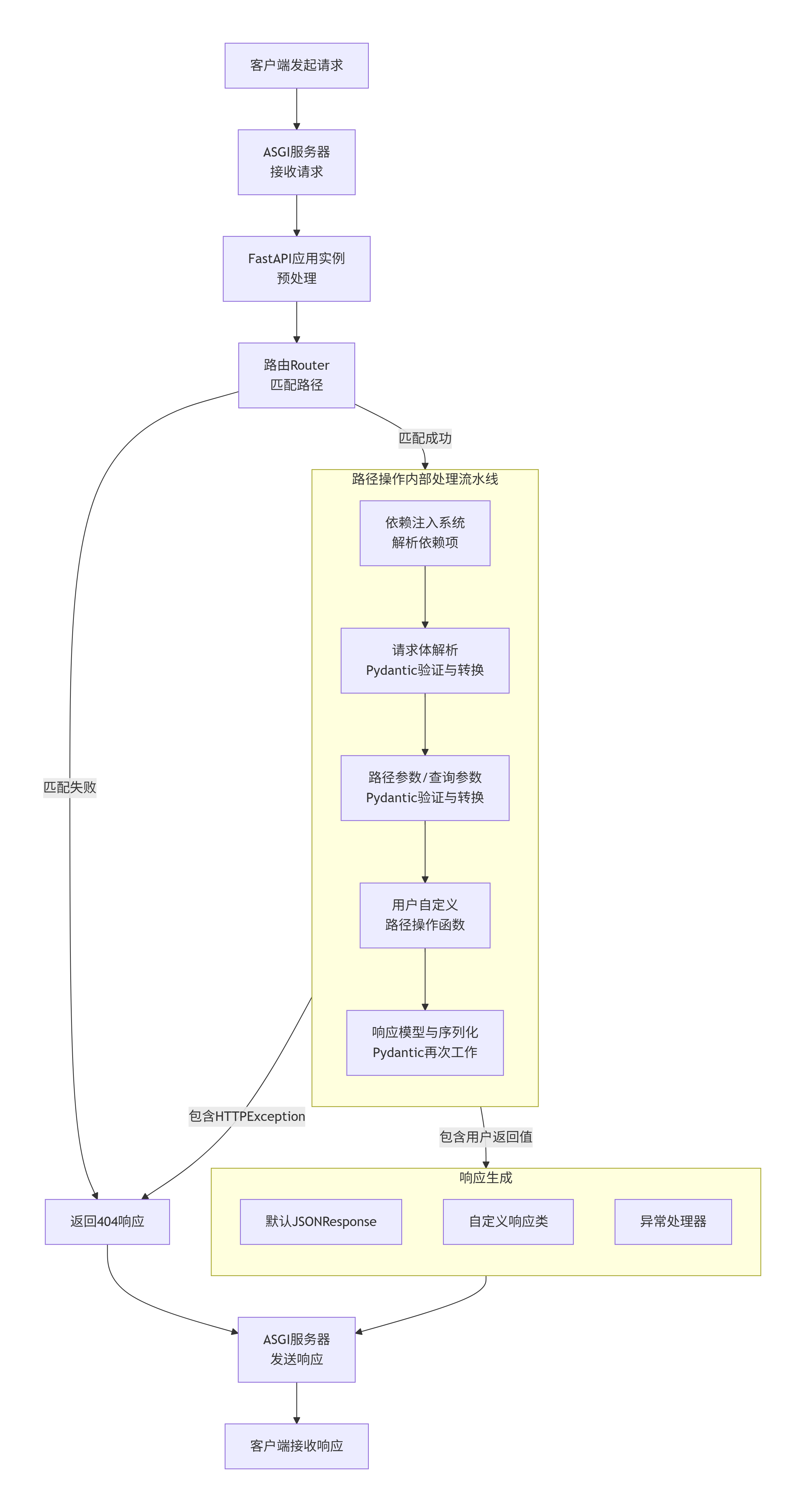
阶段一:请求接收与预处理(ASGI 服务器 & FastAPI 应用)
- ASGI 服务器接收请求:
- 流程开始于 ASGI 服务器(如 Uvicorn)。它们监听网络端口,接收来自客户端的原始 HTTP 请求。
- ASGI 服务器将请求解析为一个 ASGI 连接“范围”(
scope),其中包含了请求的方法、路径、请求头等基本信息。
- FastAPI 应用实例接管:
- ASGI 服务器调用
FastAPI应用实例(一个符合 ASGI 规范的可调用对象),并将scope、一个用于接收请求体的函数receive和一个用于发送响应的函数send传递给它。 - FastAPI 基于
scope创建一个Request对象(实际上是 Starlette 的Request对象)。这个对象封装了所有的请求信息。
- ASGI 服务器调用
阶段二:路由匹配
- 路由器(Router)匹配路径:
- FastAPI 将请求交给内部的路由器(
APIRouter)。 - 路由器根据请求的 URL 路径(
request.url.path)和 HTTP 方法(如 GET),在所有已注册的路径操作中查找匹配项。 - 如果找不到匹配的路由,FastAPI 会自动处理并返回一个 404 Not Found 响应。
- FastAPI 将请求交给内部的路由器(
阶段三:路径操作内部处理流水线
一旦找到匹配的路径(例如 @app.get("/items/{item_id}")),请求就进入了该路径操作的核心处理流水线。这是最复杂也是最具特色的一步。
- 依赖项解决:
- FastAPI 首先检查该路径操作是否声明了任何“依赖项”(
dependencies)。 - 它会按顺序执行这些依赖函数。依赖项的返回值可以被注入到路径操作函数中。
- 如果依赖项抛出
HTTPException,流程会立即中断,并跳转到异常处理部分。
- FastAPI 首先检查该路径操作是否声明了任何“依赖项”(
- 请求体解析与验证:
- 对于带有请求体(如 POST)的方法,FastAPI 会检查是否定义了 Pydantic 模型。
- 异步读取:它会异步读取请求体。
- 解析与验证:然后将读取到的原始数据(如 JSON)传递给对应的 Pydantic 模型。
- 强大的类型转换与验证:
- 验证:Pydantic 会检查数据是否符合模型中定义的字段类型和约束(例如,字符串格式、数字范围)。如果验证失败,Pydantic 会抛出
ValidationError,FastAPI 会自动将其转换为包含错误详情的 422 Unprocessable Entity 响应。 - 转换:如果验证成功,Pydantic 会将原始数据转换为 Python 对象(例如,将 JSON 字符串
"123"转换为整数123)。这个对象就是我们路径操作函数中定义的参数。
- 验证:Pydantic 会检查数据是否符合模型中定义的字段类型和约束(例如,字符串格式、数字范围)。如果验证失败,Pydantic 会抛出
- 路径参数和查询参数的解析与验证:
- 路径参数(如
/items/{item_id})和查询参数(如?skip=0&limit=10)也会经历类似的过程。 - FastAPI 根据你在函数参数中声明的类型提示(如
item_id: int,skip: int = 0),自动从请求中提取这些参数,并尝试进行类型转换和验证。 - 如果类型转换失败(例如,将
"abc"转换为int),FastAPI 会自动返回一个包含错误详情的 422 响应。
- 路径参数(如
阶段四:执行用户代码与生成响应
- 执行路径操作函数:
- 现在,所有参数都已准备就绪:依赖项的返回值、已验证的请求体对象、已验证/转换后的路径和查询参数。
- FastAPI 用这些参数调用你编写的路径操作函数。
- 函数可以是普通的同步函数,也可以是
async异步函数。FastAPI 能正确处理两者,并在需要时在线程池中运行同步函数以避免阻塞事件循环。
- 处理响应模型:
- 路径操作函数返回一个值(例如,一个 Pydantic 模型实例或一个字典)。
- FastAPI 会检查你是否为该路径定义了
response_model。 - 再次利用 Pydantic:如果定义了,返回的数据会被强制转换为
response_model的类型。这确保了响应数据符合你定义的模型,包括:- 过滤掉模型中未定义的字段。
- 对输出数据进行验证和序列化。
- 这一步保证了 API 返回数据的格式始终一致且正确。
阶段五:响应发送
- 生成响应:
- FastAPI 将最终的 Python 对象(例如,字典、列表)序列化为 JSON 字符串。
- 它创建一个
Response对象(默认是JSONResponse),设置适当的状态码、响应头(如Content-Type: application/json)等。
- 发送响应:
- 最后,FastAPI 通过 ASGI 协议,调用
send函数,将构建好的 HTTP 响应发送回 ASGI 服务器。 - ASGI 服务器最终将这个响应通过网络传回给客户端。
- 最后,FastAPI 通过 ASGI 协议,调用
错误处理贯穿始终
在整个流程中,任何地方都可能发生错误(路由不匹配、参数验证失败、依赖项出错、业务逻辑抛出异常等)。FastAPI 有一套完善的异常处理机制:
- HTTPException:在代码中抛出
HTTPException,FastAPI 会捕获它并生成对应的 HTTP 错误响应。 - 请求验证错误:由 Pydantic 或参数验证引起的
RequestValidationError会被自动捕获,并生成包含详细错误信息的 422 响应。 - 全局异常处理器:可以使用
@app.exception_handler()来自定义如何处理特定类型的异常,提供友好的错误信息。
总结
FastAPI 的处理流程是一个高效、严谨的管道: ASGI 服务器 → FastAPI → 路由匹配 → 依赖项 → 参数/请求体验证(Pydantic)→ 路径操作函数 → 响应模型(Pydantic)→ 序列化 → 响应
其核心优势在于:
- 深度集成 Pydantic:在请求入口和响应出口都进行了严格的类型验证和转换,保证了数据的可靠性和开发体验。
- 基于 ASGI:提供了异步支持,能够处理高并发 I/O 密集型请求。
- 清晰的依赖注入系统:使代码更模块化、可测试和可复用。
- 自动化文档生成:FastAPI 能自动生成准确的 OpenAPI 文档。
1.项目整体结构
1.1 顶层目录结构
project_root/
├── src/
│ └── app/ # 应用主目录
│ ├── core/ # 全局核心代码(配置、数据库、依赖等)
│ ├── modules/ # 业务模块目录,每个模块自成体系
│ ├── main.py # FastAPI 应用入口
│ └── __init__.py
├── tests/ # 测试代码
├── docs/ # 项目文档
├── worker.py # RQ (Redis Queue) worker 入口
├── Dockerfile # Docker 镜像构建文件
├── docker-compose.yml # Docker Compose 配置
├── pyproject.toml # uv/Poetry 依赖管理文件
├── uv.lock # uv lock文件,锁定依赖版本
├── alembic.ini # Alembic 配置(如用数据库迁移)
├── migrations/ # Alembic 迁移脚本目录
├── Makefile # 常用命令脚本
├── .env.example # 环境变量示例文件
├── .gitignore
└── README.md
1.2 app/目录结构
src/app/
├── core/
│ ├── config.py # 配置加载与管理
│ ├── database.py # 数据库连接与会话
│ ├── redis.py # Redis 连接与 RQ 队列
│ ├── dependencies.py # 全局依赖(如认证、权限)
│ ├── exceptions.py # 自定义异常定义
│ ├── handlers.py # 全局异常处理器
│ ├── security.py # 安全相关工具(如密码哈希、JWT 编码解码)
│ ├── logging.py # 日志配置与管理
│ └── __init__.py
│
├── modules/
│ ├── users/ # 用户模块
│ │ ├── router.py # 路由定义(APIRouter)
│ │ ├── service.py # 业务逻辑
│ │ ├── schemas.py # Pydantic 数据模型 (请求/响应/校验)
│ │ ├── models.py # SQLAlchemy ORM 数据模型 (数据库表结构)
│ │ ├── crud.py # 数据库 CRUD 操作
│ │ ├── tasks.py # 异步任务定义
│ │ └── __init__.py
│ │
│ ├── products/ # 产品模块
│ │ ├── router.py
│ │ ├── service.py
│ │ ├── schemas.py
│ │ ├── models.py
│ │ ├── crud.py
│ │ ├── tasks.py
│ │ └── __init__.py
│ │
│ └── ... # 其他业务模块
│
├── main.py # FastAPI 应用实例与路由注册
└── __init__.py
2.项目配置与.env文件的使用
不建议采用硬编码的形式将一些敏感配置信息写死在代码里,推荐使用.env文件统一管理配置信息。
2.1 创建.env文件
在项目根目录下创建.env文件(xxx需替换为你的配置信息):
# FastAPI 连接数据库的URL
# docker使用
#DATABASE_URL=mysql+pymysql://root:xxx@host.docker.internal:3306/cognitive_disorder?charset=utf8mb4
# 本地使用
DATABASE_URL=mysql+pymysql://root:xxx@localhost:3306/cognitive_disorder?charset=utf8mb4
# minio配置(若需要使用minio对象存储)
MINIO_ENDPOINT=xxx
MINIO_ACCESS_KEY=xxx
MINIO_SECRET_KEY=xxx
MINIO_SECURE=false
MINIO_BUCKET_NAME=xxx
# 若需要使用JWT验证,JWT配置
SECRET_KEY="miyue"
ALGORITHM=HS256
ACCESS_TOKEN_EXPIRE_MINUTES=240
2.2 读取.env文件
在config.py文件中,通过Pydantic的BaseSettings类实现。Pydantic 的 BaseSettings 是一个专门用于管理应用程序配置的类,它继承自 BaseModel,提供了强大的配置管理功能,特别适合处理环境变量和配置文件。
首先导入BaseSettings类,在文件中定义一个类继承自BaseSettings类,类的参数与.env文件中的配置相对应,在类中使用 model_config = {"env_file": ".env", "case_sensitive": False, "extra": "ignore"}来加载.env文件并为类中的参数赋值。接着我们创建一个类的实例,以后就可以使用这个实例来获取配置信息了。
pydantic-settings需要安装:
pip install pydantic-settings
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
# MySQL 数据库连接 URL
DATABASE_URL: str
# 告诉pydantic从.env读取
model_config = {"env_file": ".env", "case_sensitive": False, "extra": "ignore"}
# 创建配置实例,供其他地方引用
settings = Settings()
3.路径装饰器和路由分组
3.1路径装饰器
路径装饰器是用于将 URL 路径与下方的 Python 函数绑定的一种机制。它告诉 FastAPI:“当有请求访问这个特定路径时,就执行我这个被装饰的函数。” 它看起来就像 Python 的标准装饰器,使用 @app 后跟一个 HTTP 方法操作来定义。
在 FastAPI 中,这个被装饰的函数被称为路径操作函数。例如:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
当使用get方法访问根路由时,fastapi就会进行路由匹配并调用root()函数。
3.2 路由分组
使用APIRouter来实现路由分组。APIRouter 是 FastAPI 中用于组织路由的工具,它允许你将相关的路由分组在一起,使代码更加模块化和可维护。
a.创建路由器
在模块的router.py中,使用APIRouter创建路由器实例。
from fastapi import APIRouter
# 创建路由器实例
router = APIRouter()
# 在路由器上定义路由
@router.get("/items/")
async def read_items():
return [{"name": "Item 1"}, {"name": "Item 2"}]
@router.get("/items/{item_id}")
async def read_item(item_id: int):
return {"name": f"Item {item_id}", "id": item_id}
b.在主应用中包含路由器
其中,prefix=/api/v1表示此路由器中的路由全都带有/api/v1的前缀
# main.py
from fastapi import FastAPI
app = FastAPI()
# 包含路由器
app.include_router(router, prefix="/api/v1", tags=["items"])
c.路由器参数详解
# router.py
router = APIRouter(
tags=["items"], # OpenAPI 标签,用于在api文档中展示
dependencies=[], # 依赖项
)
4.启动项目与自动生成的接口文档
uvicorn <模块路径>:<应用实例名称> [选项]
# 若项目简单,main.py在根目录下
uvicorn main:app
# 如果是按照上方的项目结构
uvicorn src.app.main:app
更改端口启动:
uvicorn app.py --port 8001
主机改为0.0.0.0:
uvicorn app.py --host 0.0.0.0 --port 8001
fastapi会自动根据我们写的代码生成接口文档,方便查看接口和进行调试,在浏览器访问http://127.0.0.1:8000/docs即可查询。如果需要关闭接口文档的访问,在app实例的参数中设置:
# main.py
app = FastAPI(docs_url=None, redoc_url=None, openapi_url=None)
5.路径与查询参数
客户端可以在请求url中携带信息进行传递以查询特定数据,包含两种方式:路径参数和查询参数
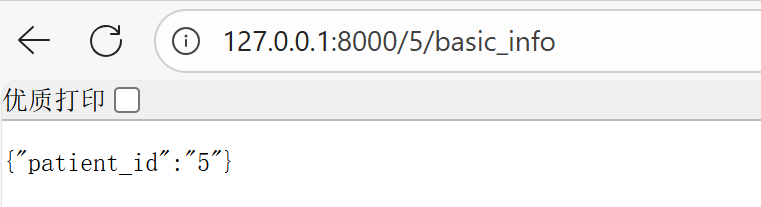
5.1 路径参数
路径参数是url中使用{}包裹的占位符,可以提取传递给路径操作函数。
@patient_info.get("/{patient_id}/basic_info", summary="获取某一位患者基本信息")
def single_basic_info(patient_id):
return {"patient_id": patient_id}
在路径操作函数中传入patient_id参数就可以获取到路由中大括号中patient_id的值。
其中url中的5便是路径参数:
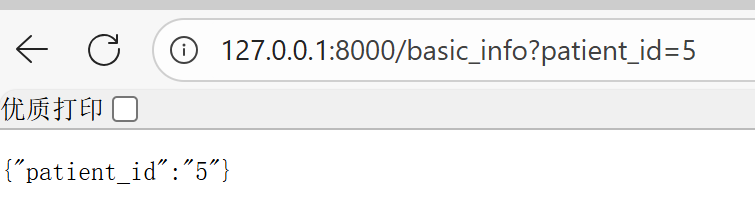
5.2 查询参数
查询参数是指url中?后面键值对中的值。我们直接在路径操作函数中接收即可。
@patient_info.get("/basic_info", summary="获取患者基本信息")
def single_basic_info(patient_id: str):
return {"patient_id": patient_id}
6.Pydantic模型
6.1 什么是 Pydantic?
Pydantic 是一个用来执行数据校验的 Python 库。你可以将数据的"结构"声明为具有属性的类。每个属性都拥有类型。
接着你用一些值来创建这个类的实例,这些值会被校验,并被转换为适当的类型(在需要的情况下),返回一个包含所有数据的对象。
FastAPI 深度集成了 Pydantic,将其作为处理所有数据验证、序列化和文档生成的基础。
6.2 为什么在 FastAPI 中使用 Pydantic 模型?
在没有 Pydantic 之前,我们可能需要写大量的 if 语句来检查请求数据是否有效。Pydantic 和 FastAPI 的结合带来了以下巨大优势:
- 声明式验证:使用 Python 类型提示来定义数据模型,代码简洁、直观、易于维护。
- 自动验证:当数据到达你的 API 端点时,FastAPI 会自动使用你定义的 Pydantic 模型对其进行验证。如果数据无效,它会自动返回一个包含错误详情的 422 Unprocessable Entity 响应。
- 数据转换:自动将来自 JSON 的原始数据转换为对应的 Python 数据类型(如将 ISO 格式的字符串转换为
datetime对象)。 - OpenAPI 文档集成:FastAPI 使用你的 Pydantic 模型自动生成交互式 API 文档(Swagger UI 和 ReDoc),包括请求/响应体的结构、数据类型、是否必填等,极大减少了编写文档的工作量。
6.3 基础使用
a.接收并验证form-data数据
Pydantic模型全部放在schemas.py中,username和password是通过fastapi的form组件接收的(form组件后面在如何接收请求体数据时会说到),分别为用户在表单中输入的用户名和密码。
# schemas.py
from pydantic import BaseModel
class LoginForm(BaseModel):
username: str
password: str
from fastapi import FastAPI, Form
app = FastAPI()
@app.post("/login")
async def login(
username: str = Form(...),
password: str = Form(...)
):
# 手动创建 Pydantic 模型实例进行验证
form_data = LoginForm(username=username, password=password)
return {"message": f"Welcome {form_data.username}"}
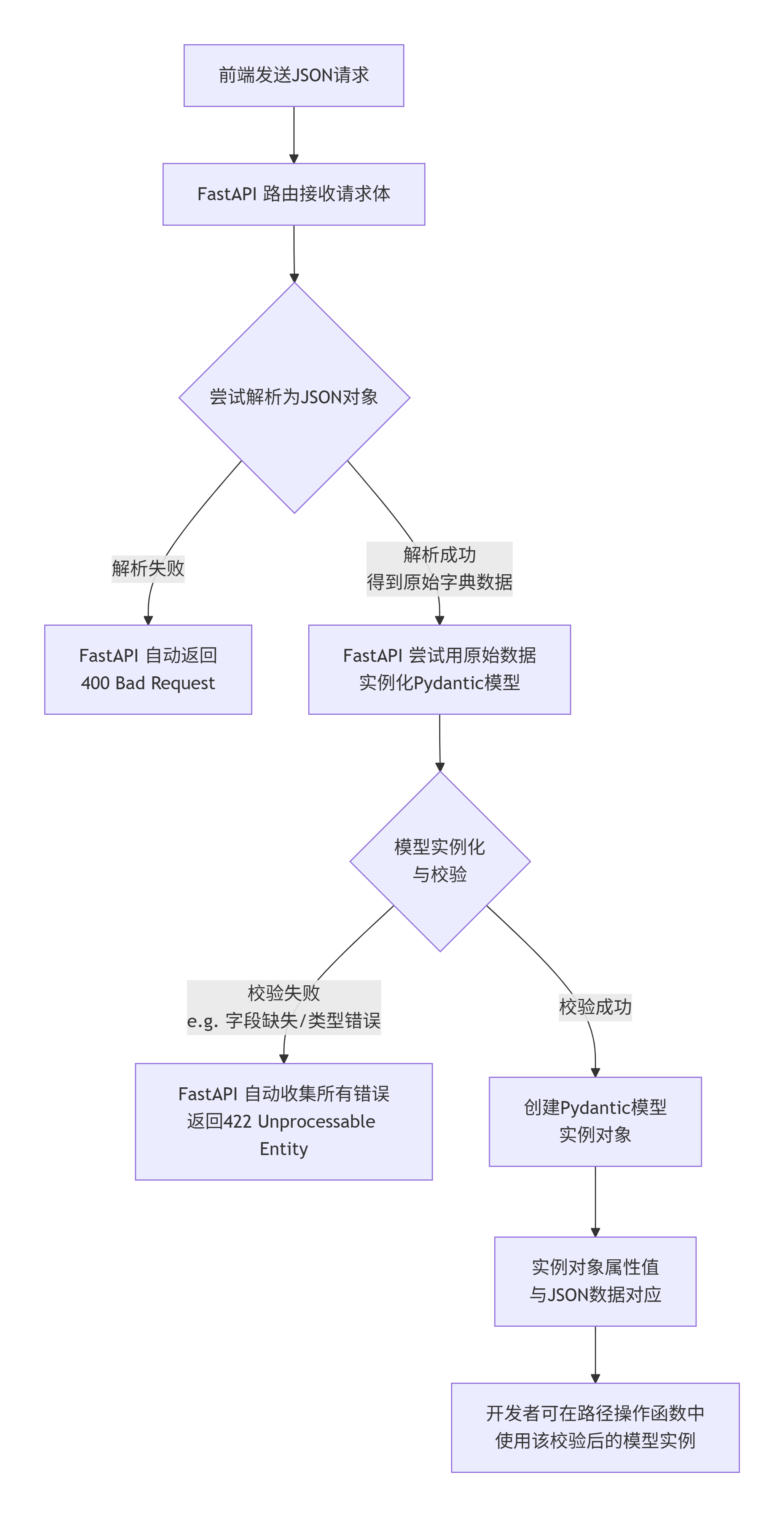
b.接收并验证json数据
from pydantic import BaseModel
class UserSchema(BaseModel):
name: str
age: int
friends: list[int]
这里我们定义了一个用户基本信息的Pydantic模型类。name设置为字符串类型,age设置为整型,friends设置为列表,列表中的值为整型。这就要求前端传来的json数据中必须含有这三个字段且类型必须为设置的类型,否则会报422错误。
在路由中使用它:
# router.py
@user.post("/user")
def create_user(data:UserSchema):
return {"username":data.name, "age":data.age, "friends":data.friends}
在路径操作函数的参数中,data: UserSchema意思是我们使用请求体中的json数据来创建一个Pydantic模型类的实例,这个过程中会对json数据进行字段是否缺失,数据类型是否正确进行校验,成功后data就是基于我们定义的Pydantic类创建的对象,这个对象的属性值对应json数据中的值,校验失败会返回422错误,不会进入到路径操作函数。打开postman进行测试:
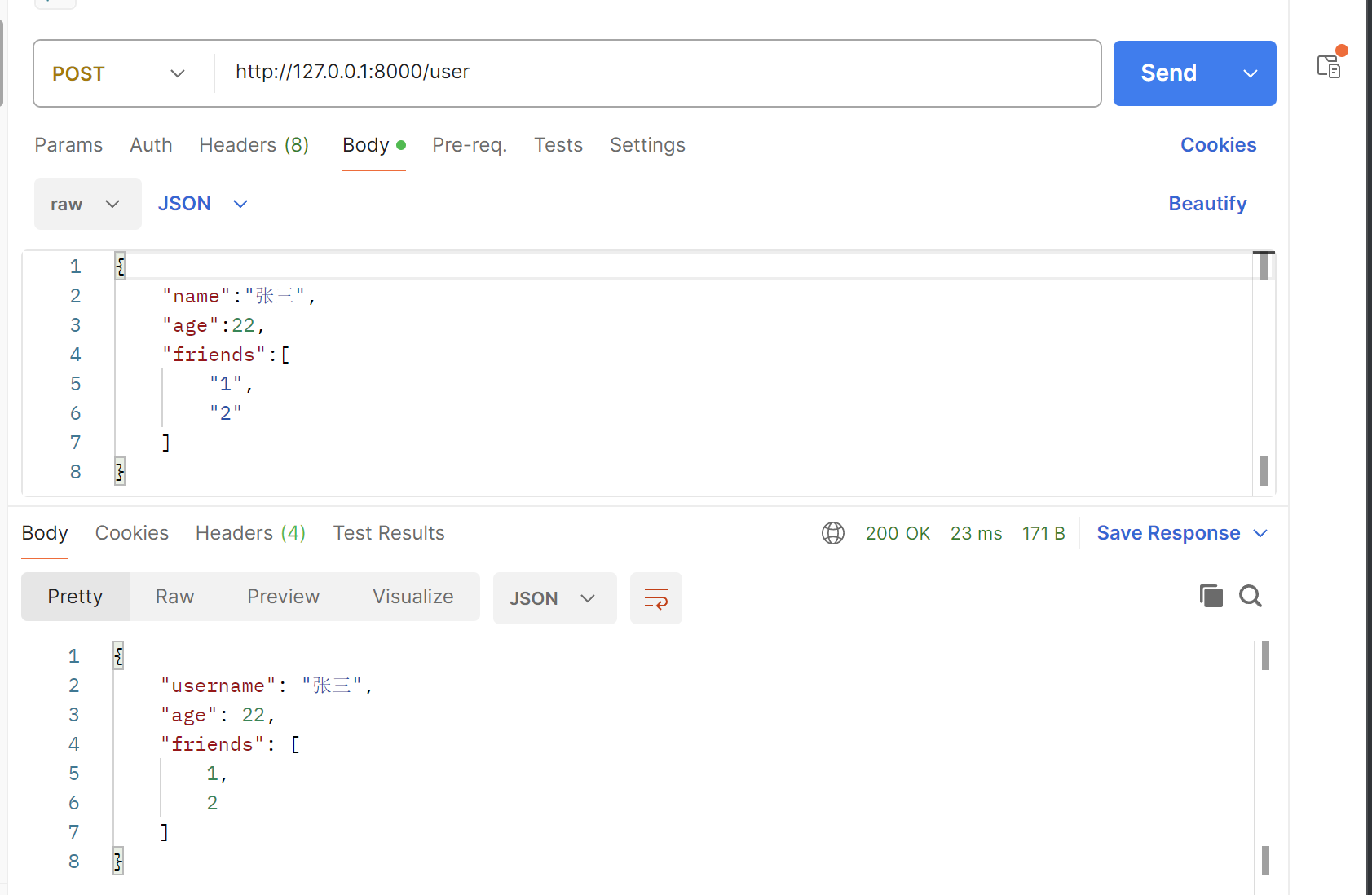
当我们发送错误数据时(将name的值改为数字5进行传递):
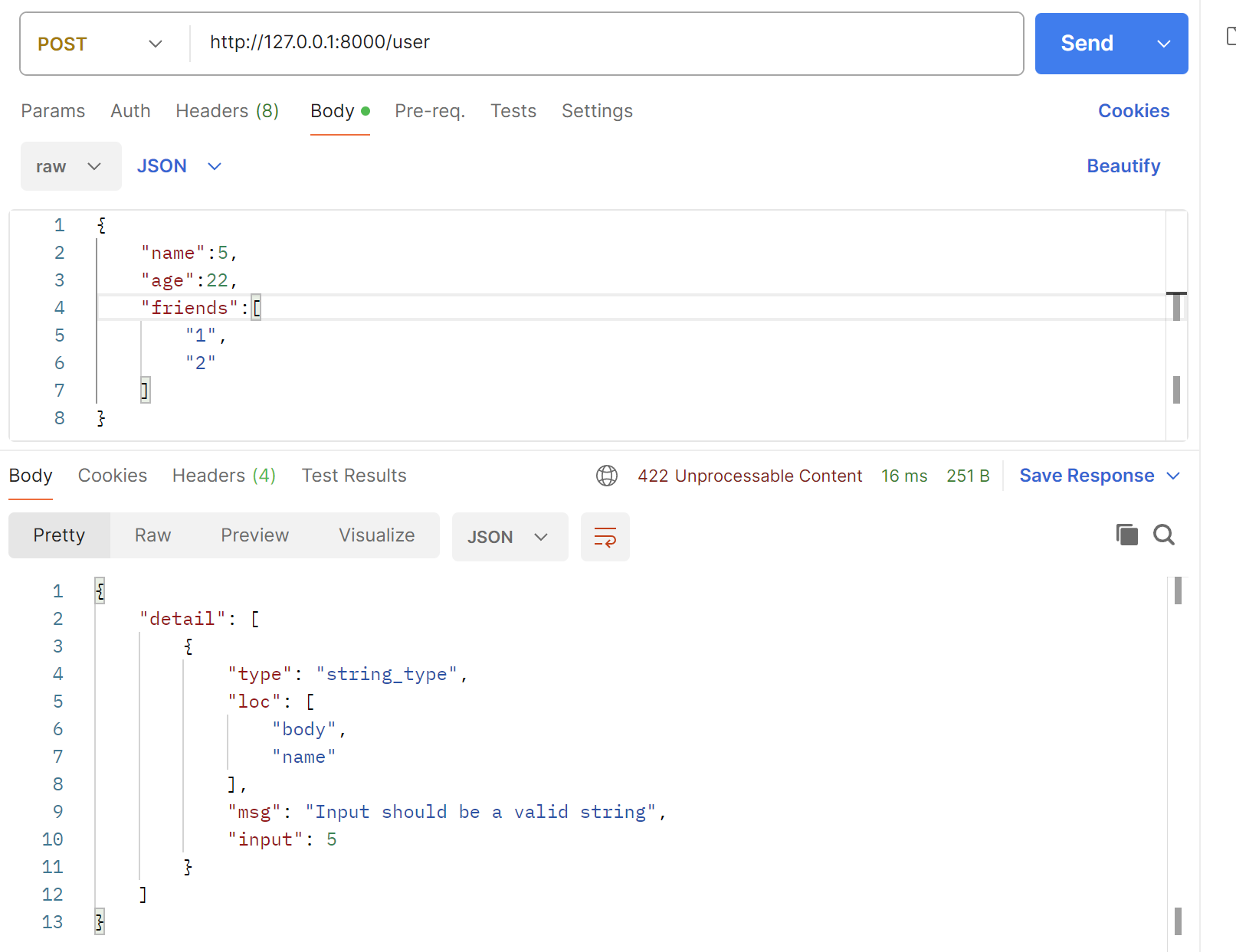
当我们缺少字段时(缺少name字段):
c.进行配置管理设置
在上面读取.env文件小节中。
6.4 Pydantic校验类型归纳
基础标量类型
| 类型 | 描述 | 常用校验参数 |
|---|---|---|
str |
字符串 | min_length, max_length, regex |
constr |
约束字符串 | min_length, max_length, regex, strip_whitespace |
int |
整数 | 无 |
conint |
约束整数 | ge, gt, le, lt, multiple_of |
float |
浮点数 | 无 |
confloat |
约束浮点数 | ge, gt, le, lt, multiple_of |
bool |
布尔值 | 无 |
Decimal |
高精度小数 | max_digits, decimal_places |
容器类型
| 类型 | 描述 | 常用校验参数 |
|---|---|---|
List[T] |
列表 | 无 |
conlist(T) |
约束列表 | min_items, max_items |
Set[T] |
集合 | 无 |
Dict[K, V] |
字典 | 无 |
Tuple |
元组 | 无 |
Sequence[T] |
序列 | 无 |
FrozenSet[T] |
不可变集合 | 无 |
可选和默认值
| 类型 | 描述 |
|---|---|
Optional[T] |
可选字段(可None) |
T = default |
带默认值字段 |
Required |
必需字段标记 |
7.请求数据
7.1 Request对象
a. 什么是 Request 对象?
在 FastAPI 中,Request 对象是一个非常重要的组件,它封装了一个 HTTP 请求的全部信息。当客户端(如浏览器、移动应用等)向你的服务器发送一个请求时,FastAPI 会自动创建一个 Request 对象,并将它作为参数传递给你的路径操作函数(如果你声明了的话)。
这个对象直接来自于 Starlette(FastAPI 构建于其之上),所以你获得的是 Starlette 的 Request 类所有强大而灵活的功能。
b. 如何获取 Request 对象?
你只需要在路径操作函数中将其声明为一个参数即可。
from fastapi import FastAPI, Request
app = FastAPI()
@app.get("/")
async def read_root(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
FastAPI 的依赖注入系统会识别这个参数,并在调用你的函数时自动提供正确的 Request 对象。
c. Request 对象的主要属性和方法
Request 对象包含了海量的信息,以下是一些最常用和最重要的部分。
基本属性
-
request.method: 获取请求的 HTTP 方法(如"GET","POST","PUT","DELETE")。 -
request.url: 一个包含完整 URL 的对象(例如http://localhost:8000/items?q=foo)。request.url.path: URL 的路径部分(如/items)。request.url.query: 查询字符串(如q=foo)。request.url.scheme: 协议(如"http","https")。request.url.hostname: 主机名(如"localhost")。request.url.port: 端口号(如8000)。
-
request.headers: 一个只读的、类似字典的对象,包含所有的 HTTP 请求头。user_agent = request.headers.get('user-agent') -
request.client: 包含客户端连接信息(如 IP 地址和端口)的对象。request.client.host: 客户端的 IP 地址(如"192.168.1.1")。request.client.port: 客户端的端口号。
请求体
-
request.body(): 一个异步函数,返回原始的字节序列形式的请求体。对于大文件上传等场景很有用。body_bytes = await request.body() -
request.json(): 一个异步函数,如果请求体是 JSON,则解析并返回 Python 对象(如dict,list)。body_data = await request.json() -
request.form(): 一个异步函数,解析表单数据(application/x-www-form-urlencoded或multipart/form-data),返回一个类似字典的对象。form_data = await request.form() name = form_data.get("name")
7.2 获取普通form-data数据
使用Form参数,在函数参数中使用xxx: 参数类型 = Form(...)其中xxx是字段名,需与form-data中的key的值相对应(三个点表示必传)
如果想给字段值默认值,则xxx:字段类型 = Form(default=xxx),若想将默认值设为空,则Form(None)
from fastapi import FastAPI, Form
app = FastAPI()
@app.post("/login/")
async def login(username: str = Form(...), password: str = Form(...)):
return {
"username": username,
"password": password
}
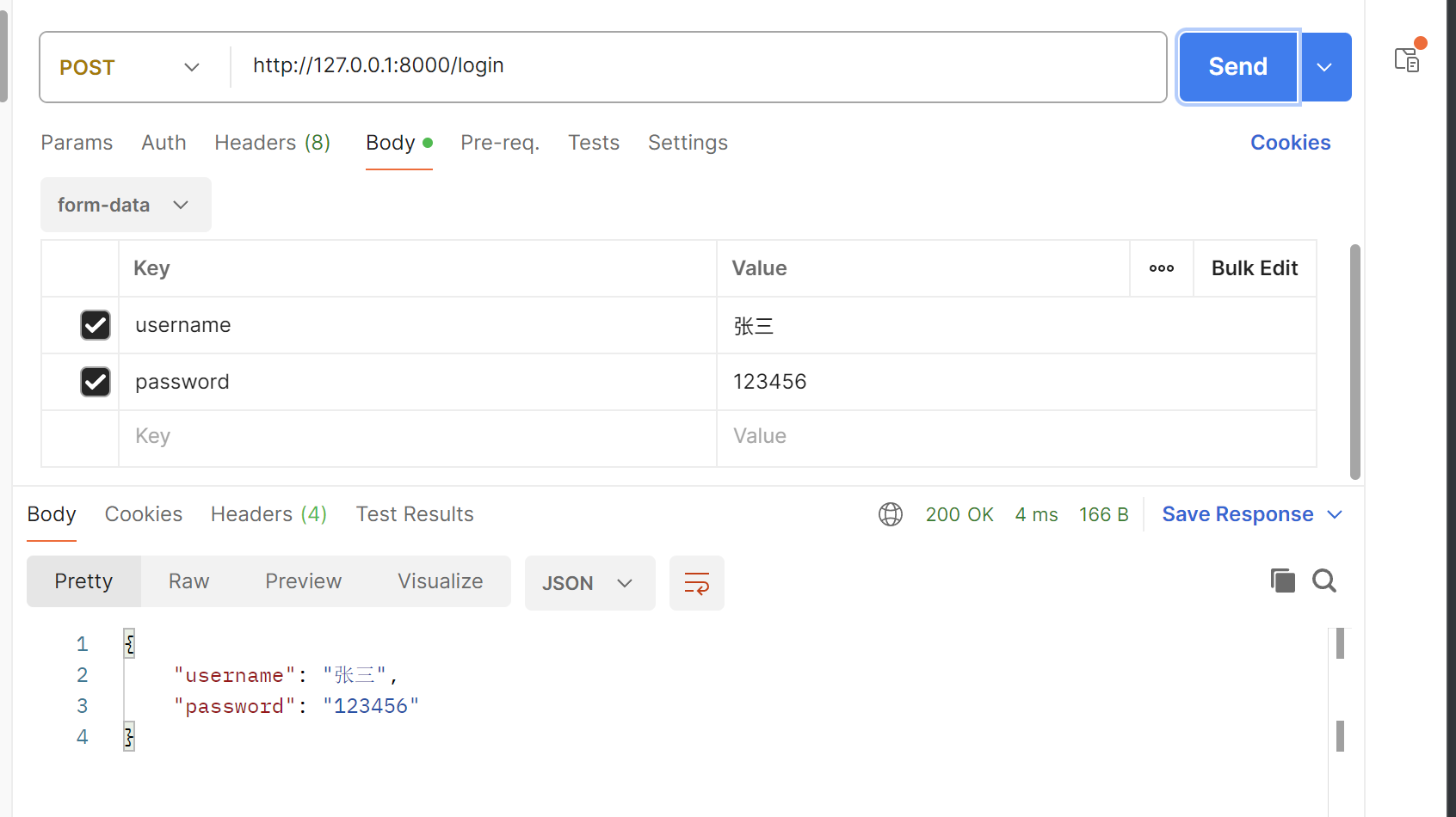
7.3 获取文件
a.直接使用File
特点:
- 返回文件的原始字节内容 (
bytes) - 文件内容完全加载到内存中
- 适合小文件处理
- 使用简单直接
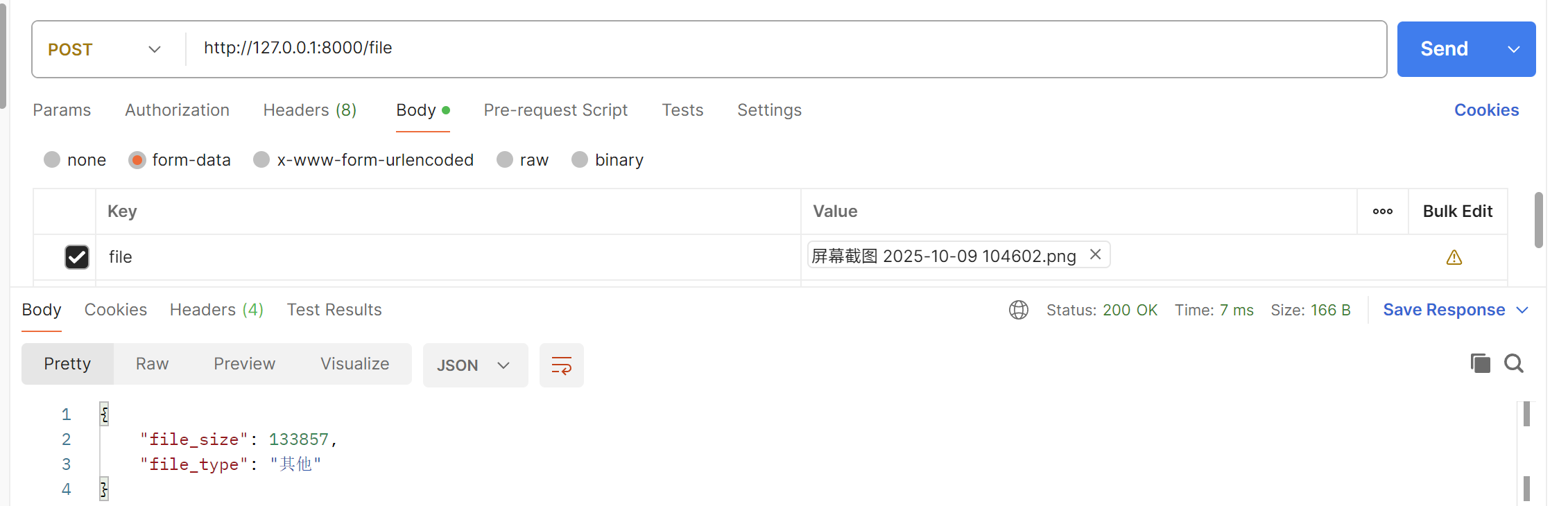
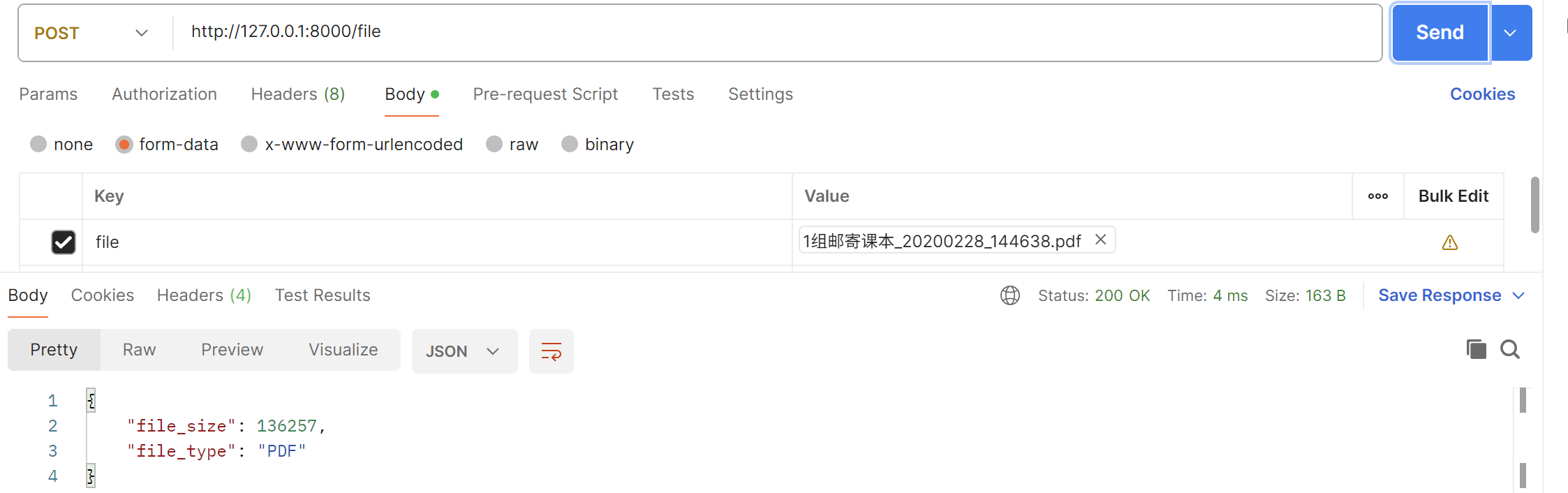
@app.post("/file")
async def upload_file(file: bytes = File(...)):
# file 是 bytes 类型
file_size = len(file)
# 可以直接处理字节数据
if file.startswith(b'%PDF'):
file_type = "PDF"
else:
file_type = "其他"
return {"file_size": file_size, "file_type": file_type}
b.使用UploadFile
特点:
- 返回一个文件对象,支持流式处理
- 文件可以存储在内存或临时文件中
- 适合大文件处理
- 提供更多文件元数据和方法
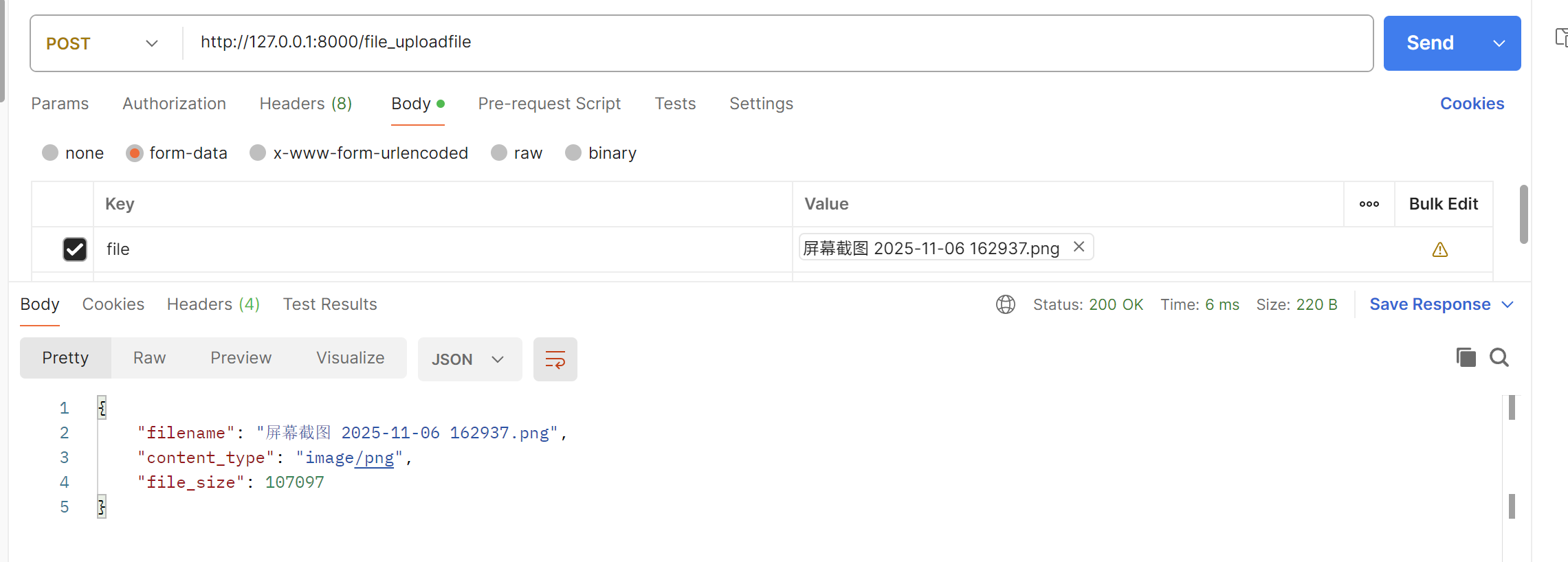
@app.post("/file_uploadfile")
async def upload_file_by_uploadfile(file: UploadFile = File(...)):
# 访问文件属性
filename = file.filename
content_type = file.content_type
# 读取文件内容(可以分块读取)
content = await file.read()
# 或者使用分块读取来处理大文件
# chunk_size = 1024 * 1024 # 1MB
# while chunk := await file.read(chunk_size):
# # 处理每个块
return {
"filename": filename,
"content_type": content_type,
"file_size": len(content)
}
c.接收文件加表单数据
from fastapi import FastAPI, File, UploadFile, Form
from typing import Optional
app = FastAPI()
@app.post("/upload/")
async def upload_file(
file: UploadFile = File(...),
description: str = Form(""),
tags: str = Form("")
):
return {
"filename": file.filename,
"description": description,
"tags": tags.split(",") if tags else []
}
d.接收多个同名文件
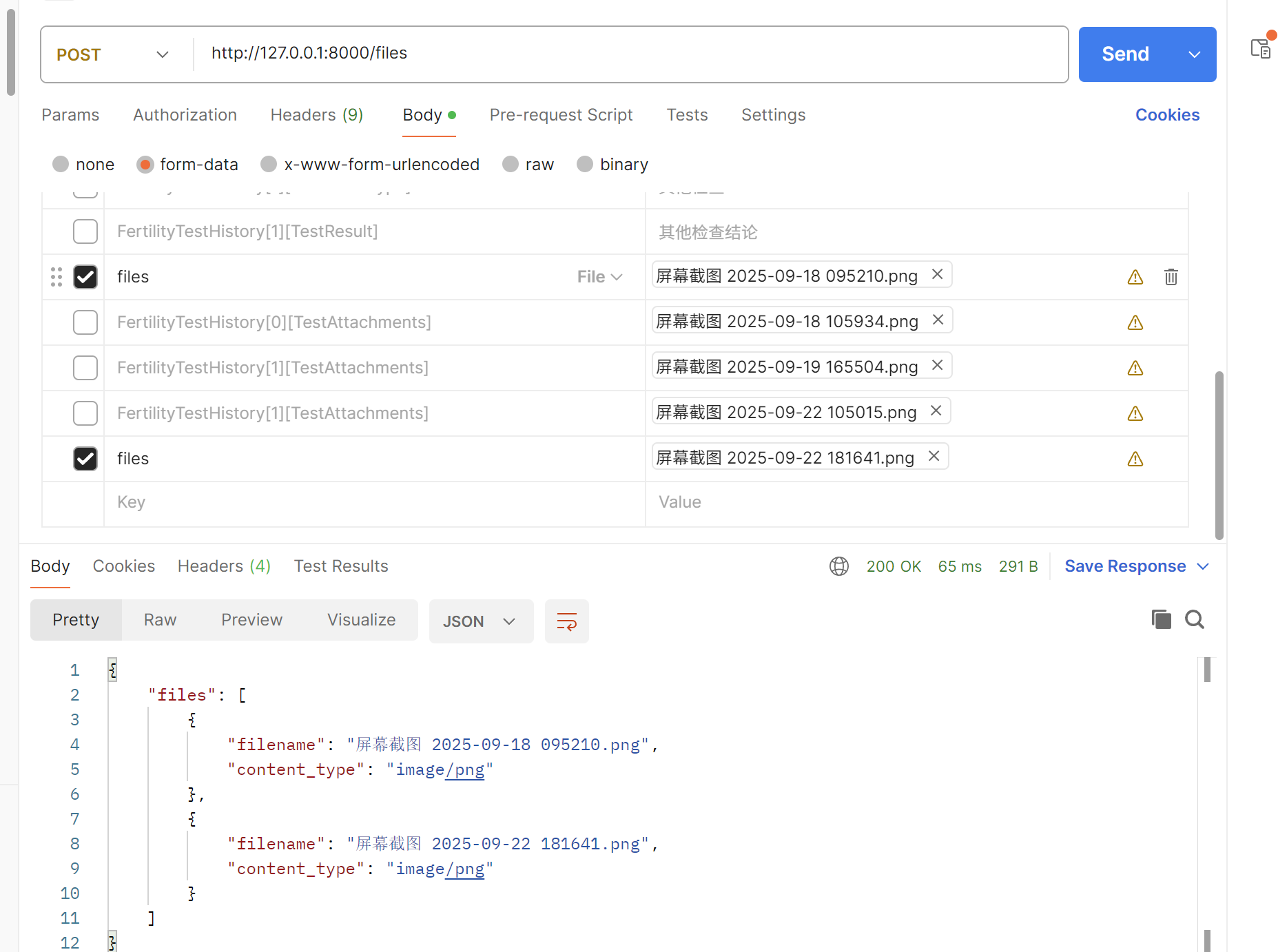
这里我们上传了两张图片,form-data的Key都为files。
@app.post("/files")
def upload_files(files: List[UploadFile] = File(...)):
file_info = []
for file in files:
contents = file.read()
file_info.append({
"filename": file.filename,
"content_type": file.content_type
})
# 重置文件指针,以便后续读取
file.seek(0)
return {"files": file_info}
e.接收多个不同名文件
1.使用多个File参数
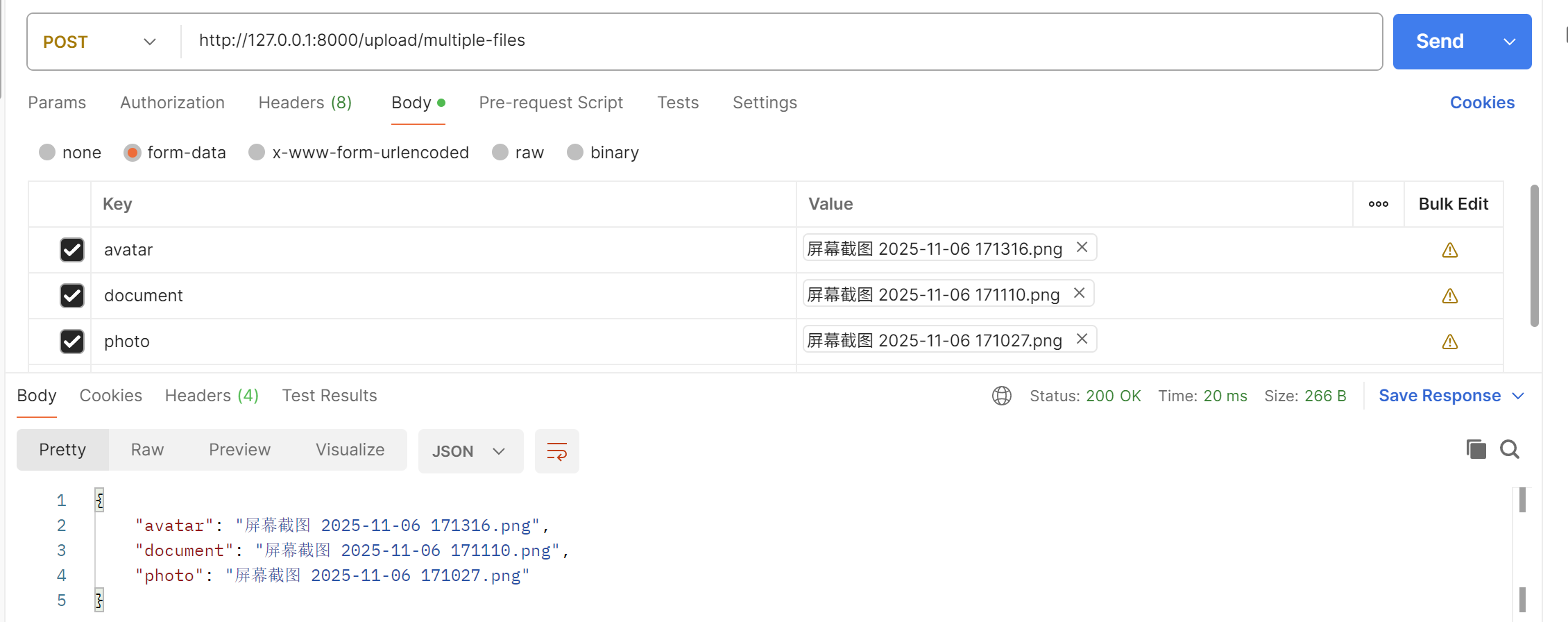
@app.post('/upload/multiple-files')
def upload_multiple_files(avatar: UploadFile = File(...), document: UploadFile = File(...),
photo: UploadFile = File(...)):
return {
"avatar": avatar.filename,
"document": document.filename,
"photo": photo.filename
}
2.使用字典动态接收
from starlette.datastructures import UploadFile as StarletteUploadFile
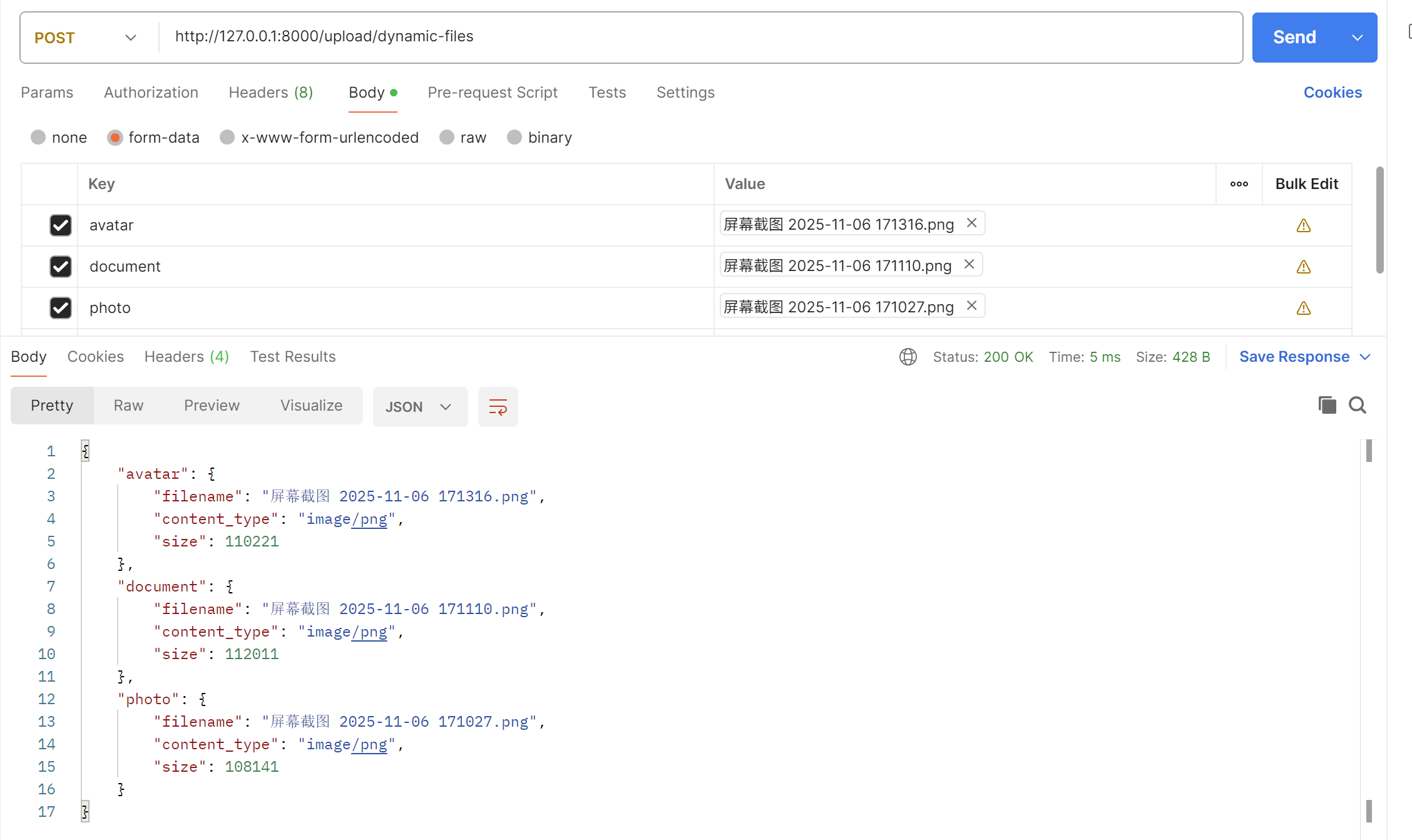
@app.post('/upload/dynamic-files')
async def upload_dynamic_files(request: Request):
form_data = await request.form()
result = {}
# 遍历表单数据的键和值
for field_name, value in form_data.items():
print(field_name)
# 使用正确的类型检查
if isinstance(value, StarletteUploadFile):
content = await value.read()
result[field_name] = {
"filename": value.filename,
"content_type": value.content_type,
"size": len(content)
}
await value.seek(0)
return result
注意if isinstance(value, StarletteUploadFile):这行代码,我起初是使用的if isinstance(value, UploadFile):,结果我上传的文件都没有被认为是UploadFile而通过判断语句,经过调试发现,从form_data中取到的文件类型为StarletteUploadFile,这和Fastapi的UploadFile功能相似但被python认为是不同的类型。
上面代码中form_data = await request.form() 返回的 是**starlette.datastructures.FormData** 对象。这是Starlette框架专门用于处理 multipart/form-data 格式数据的类。
FormData内部存储结构大致如下:
{
"avatar": <UploadFile对象>,
"username": "john_doe",
"email": "john@example.com"
}
# 常用方法
@app.post('/example')
async def example(request: Request):
form_data = await request.form()
# 1. items() - 返回所有键值对
print("=== items() ===")
for key, value in form_data.items():
print(f"{key}: {value} (类型: {type(value)})")
# 2. keys() - 返回所有字段名
print("=== keys() ===")
for key in form_data.keys():
print(f"字段: {key}")
# 3. values() - 返回所有值
print("=== values() ===")
for value in form_data.values():
print(f"值: {value} (类型: {type(value)})")
# 4. get() - 获取特定字段
print("=== get() ===")
avatar = form_data.get("avatar")
if avatar:
print(f"avatar: {avatar.filename}")
# 5. 字典式访问
print("=== 字典式访问 ===")
if "avatar" in form_data:
avatar_file = form_data["avatar"]
print(f"avatar文件名: {avatar_file.filename}")
return {"success": True}
- 专门的数据结构:为处理HTTP表单数据设计
- 混合类型容器:可以同时包含字符串和文件对象
- 类字典接口:支持
items(),keys(),values(),get()等方法 - 异步支持:需要
await来获取 - multipart/form-data 专用:处理文件上传+文本字段的混合表单
7.4 获取json数据
在上面Pydantic模型的基础使用验证json数据小节说到。
8.响应
8.1 直接返回数据
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
is_offer: bool = False
@app.get("/items/{item_id}")
async def read_item(item_id: int):
return {"item_id": item_id, "name": "Example Item"}
@app.post("/items/")
async def create_item(item: Item):
return item # 自动序列化为JSON
8.2 使用Response参数
from fastapi import FastAPI, Response
import json
app = FastAPI()
@app.get("/custom-response/")
async def custom_response(response: Response):
response.headers["X-Custom-Header"] = "CustomValue"
response.status_code = 201
return {"message": "Custom response"}
8.3 设置响应状态码
在装饰器方法中使用status_code参数。
from fastapi import FastAPI, status
app = FastAPI()
@app.post("/items/", status_code=status.HTTP_201_CREATED)
async def create_item(name: str):
return {"name": name, "id": 1}
@app.get("/items/{item_id}", status_code=status.HTTP_200_OK)
async def read_item(item_id: int):
if item_id == 0:
return {"error": "Item not found"}
return {"item_id": item_id}
@app.delete("/items/{item_id}", status_code=status.HTTP_204_NO_CONTENT)
async def delete_item(item_id: int):
# 删除操作,返回空内容但状态码为204
return
8.4 设置响应头
from fastapi import FastAPI, Response
app = FastAPI()
@app.get("/items/")
async def read_items(response: Response):
response.headers["X-Total-Count"] = "100"
response.headers["X-Custom-Header"] = "MyValue"
response.headers["Cache-Control"] = "max-age=3600"
return {"items": []}
8.5 设置 Cookies
from fastapi import FastAPI, Response
app = FastAPI()
@app.post("/login/")
async def login(response: Response):
response.set_cookie(key="session_id", value="abc123", max_age=3600)
response.set_cookie(
key="user_pref",
value="dark_mode",
httponly=True,
secure=True
)
return {"message": "Login successful"}
@app.post("/logout/")
async def logout(response: Response):
response.delete_cookie(key="session_id")
return {"message": "Logout successful"}
8.6 自定义响应模型
from fastapi import FastAPI
from pydantic import BaseModel
from typing import Optional
app = FastAPI()
class SuccessResponse(BaseModel):
success: bool
message: str
data: Optional[dict] = None
class ErrorResponse(BaseModel):
success: bool = False
error: str
code: int
@app.get("/standard-response/", response_model=SuccessResponse)
async def standard_response():
return SuccessResponse(
success=True,
message="Operation successful",
data={"item_id": 1, "name": "Example"}
)
@app.get("/error-response/", response_model=ErrorResponse)
async def error_response():
return ErrorResponse(
error="Item not found",
code=404
)
8.7 异常错误处理
HTTPException是FastAPI中用于处理HTTP错误的异常类。当你在处理请求时遇到异常情况,可以抛出HTTPException, FastAPI将自动使用合适的HTTP状态码和响应体返回给客户端。以下是一些详细的说明:
- HTTPException是一个派生自BaseException的异常类,但它同时可以把异常信息作为HttpResponse返回。
- HTTPException是一个常规的Python异常,但是它包含了额外的和API相关的数据。因为它是一个Python异常,你不返回它,你抛出它。
- 当客户端请求一个不存在的item时,触发状态码为404的异常:raise HTTPException(status_code=404, detail="Item not found")
参数详解:
class HTTPException(Exception):
def __init__(
self,
status_code: int, # HTTP 状态码(必需)
detail: Any = None, # 错误详情(必需,但可为 None)
headers: dict = None # 自定义响应头(可选)
):
9.依赖注入
9.1 一句话概念
FastAPI 的依赖注入 = 把“视图函数”里反复出现的「可复用逻辑」抽出来,写成“依赖函数”,由框架在每次请求时自动调用并把结果注入给视图函数。 核心公式: 依赖函数 → 返回值 → 视图参数(框架帮你把“返回值”塞进视图参数,你只管写业务)
9.2 为什么非用不可
- 复用:JWT 校验、分页、数据库会话、权限……写一次,处处注入。
- 解耦:视图只关心“业务”,不操心“token 怎么验、DB 怎么拿”。
- 性能:依赖结果默认在一次请求内缓存(可关),不会重复算。
- 自动生成文档:依赖里声明的 Query/Header/Body 参数会自动出现在 OpenAPI 文档。
9.3 最小可运行模板(3 行就能跑)
from fastapi import Depends, FastAPI
app = FastAPI()
# 1. 写依赖函数
def get_query_page(page: int = 1) -> int:
return page
# 2. 在路径操作函数里声明依赖
@app.get("/items")
async def list_items(page: int = Depends(get_query_page)):
return {"page": page, "data": []}
运行后访问 /items?page=3,FastAPI 会把 3 注入给 page,并自动校验类型、生成文档。
9.4 依赖到底能干什么
a. 共享数据库会话
from sqlalchemy.orm import Session
from .database import SessionLocal
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users")
def create_user(user: UserCreate, db: Session = Depends(get_db)):
...
b.用户认证
# 全局认证依赖
def get_current_user(payload=Depends(verify_token), db: Session = Depends(get_db)):
"""
通过验证 Authorization header 中的 token 获取当前用户。
"""
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
user_id = payload.get("sub")
if user_id is None:
raise credentials_exception
user = get_user(db, user_id)
if user is None:
raise credentials_exception
return user
except Exception:
raise credentials_exception
@person.get('/persons/self')
def get_person_self(current_user: Annotated[User, Depends(get_current_user)], db: Session = Depends(get_db)):
return service.get_person_self(current_user, db)
c.路径装饰器级依赖(整组路由共用)
from fastapi import APIRouter
router = APIRouter(dependencies=[Depends(get_current_user)])
from fastapi import FastAPI, Depends, APIRouter, HTTPException
app = FastAPI()
# 1. 假设的鉴权依赖
def get_current_user(token: str = Depends(oauth2_scheme)):
if token != "42":
raise HTTPException(401, "token 无效")
return {"user_id": 7, "name": "alice"}
# 2. 重点:把依赖挂到路由器
router = APIRouter(
dependencies=[Depends(get_current_user)] # ← 今天的主角
)
# 3. 再挂两个子路由
@router.get("/profile")
def profile():
# 注意:这里并没有声明 user 参数!
return {"msg": "个人中心"}
@router.get("/order")
def order():
return {"msg": "订单页"}
# 4. 把路由器注册到主应用
app.include_router(router, prefix="/user", tags=["user"])
“只要访问 /user/* 下的任何端点,FastAPI 都会先执行 get_current_user,只有不抛异常才继续分发到对应视图;依赖的返回值默认不会自动塞进视图参数,除非你在视图里再显式声明一次。”
执行时机与缓存规则
- 每次请求进入
/user/*时,框架会收集:- 路由器级依赖
- 路径装饰器级依赖(
@router.get(..., dependencies=[...])) - 视图函数级依赖 把它们排成一条链,按声明顺序执行。
- 同一请求内,同一个依赖函数实例默认缓存(
use_cache=True)。 例:如果路由器级和视图级都写了Depends(get_current_user),只会跑一遍。 - 依赖里如果抛了
HTTPException(或自定义异常),立即 422/401/403 返回,视图代码不会被执行。
返回值去哪儿了?
-
路由器级依赖的返回值不会自动注入到视图参数;它只是做“前置检查”。
-
如果你想在视图里用到用户对象,有两种写法:
-
再声明一次(利用缓存,不会重复跑)
@router.get("/profile") def profile(user=Depends(get_current_user)): # 第二次依赖,直接命中缓存 return {"msg": f'{user["name"]} 的个人中心'} -
使用
request.state手动塞(进阶) 在依赖里request.state.user = user,视图里user = request.state.user。
-
10.数据库配置与ORM操作
10.1 数据库配置
在需要操作数据库的路径操作函数中,都需要注入数据库会话依赖,如果在会话依赖函数中为db = SessionLocal(),则以后的数据库操作都为db.add,db.query,db.delete等等。
# database.py
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, Session
from src.app.core.config import settings
# 配置连接参数
SQLALCHEMY_DATABASE_URL = settings.DATABASE_URL
# 创建engine对象
engine = create_engine(
SQLALCHEMY_DATABASE_URL,
pool_pre_ping=True # 保持数据库连接活跃
)
# 创建会话
SessionLocal = sessionmaker(autocommit=False, autoflush=True, bind=engine)
# 声明基类,所有模型继承此类
Base = declarative_base()
# 数据库会话依赖
def get_db() -> Session:
db = SessionLocal()
try:
yield db
finally:
db.close()
create_engine: 创建数据库引擎,负责与数据库建立连接。declarative_base: 返回一个基类,用于定义 ORM 模型(即数据库表对应的 Python 类)。sessionmaker: 用于创建会话工厂(Session Factory),后续通过它生成具体的数据库会话对象。Session: 是 SQLAlchemy ORM 中会话类的类型提示(Type Hint)。
engine:
engine是 SQLAlchemy 与数据库通信的核心对象。- 它管理连接池(Connection Pool),而不是每次请求都新建连接。
pool_pre_ping=True:在每次从连接池取出连接前,先发一个轻量级 ping(如SELECT 1)验证连接是否有效,避免使用已断开的连接(比如数据库重启后)。
sessionmaker的参数:
bind=engine:将会话绑定到前面创建的 engine。autocommit=False:禁用自动提交,必须显式调用db.commit()才会提交事务(推荐做法,避免意外写入)。autoflush=True:在查询前自动将 pending 的对象变更同步到数据库(但不 commit)。例如你add()了一个对象,接着查询,会自动 flush 保证查询结果包含新对象。
Base基类:
Base是所有 ORM 模型类的父类。- 当你定义模型时,继承
Base,SQLAlchemy 就能自动收集表结构信息。
get_db函数:
- 这是一个 generator 函数,用于在 Web 框架(如 FastAPI)中作为依赖注入(Dependency Injection)提供数据库会话。
yield db:将db会话“交给”调用者(如路由处理函数)使用。finally: db.close():确保无论是否发生异常,都会关闭会话,释放连接回连接池。
为什么用 yield?
- 在 FastAPI 中,Depends(get_db),会:
- 调用
get_db(),进入函数; - 执行到
yield db,暂停并将db注入到路由函数; - 路由函数执行完毕后,继续执行
finally块,关闭会话。
- 调用
10.2 ORM(使用SQLAlchemy)
a.orm是什么
ORM 的全称是 Object-Relational Mapping,中文为 “对象-关系映射”。
它是一种编程技术,用于在面向对象的编程语言中的对象和关系型数据库(如 MySQL, PostgreSQL, SQLite)中的表之间建立一座桥梁,实现自动映射。简单来说,ORM 让你能够像操作普通编程语言中的对象一样,来操作数据库里的数据,而不用直接编写复杂的 SQL 语句。
b.核心思想:映射
让我们通过一个具体的例子来理解这个“映射”关系。
假设我们有一个数据库表 users:
| id | name | age | |
|---|---|---|---|
| 1 | 张三 | 25 | zhangsan@email.com |
| 2 | 李四 | 30 | lisi@email.com |
在面向对象的 Python 中,我们想用一个 User 类来表示一个用户:
class User:
def __init__(self, id, name, age, email):
self.id = id
self.name = name
self.age = age
self.email = email
ORM 的核心工作就是在这两者之间建立对应关系:
| 数据库 (Relational) | ⇄ 映射 ⇄ | 编程语言 (Object) |
|---|---|---|
| 表 (Table) | ⇄ | 类 (Class) |
| 表中的一行 (Row) | ⇄ | 对象 (Instance) |
| 表中的一列 (Column) | ⇄ | 对象的属性 (Attribute) |
所以,上面那张 users 表,通过 ORM,在代码中就变成了一个 User 类。表中的每一行数据,都可以被实例化为一个 User 对象。
c.安装依赖
pip install sqlalchemy
d.编写orm模型
# models.py
from sqlalchemy import Column, Integer, String, TIMESTAMP
from sqlalchemy.sql import func
from src.app.core.database import Base
import uuid
class User(Base):
"""用户信息表"""
__tablename__ = 'users'
id = Column(Integer, primary_key=True, autoincrement=True)
user_id = Column(String(36), unique=True, nullable=False, default=lambda: str(uuid.uuid4()))
phone_number = Column(String(11), unique=True, nullable=False)
password = Column(String(255), nullable=False)
created_at = Column(TIMESTAMP, nullable=False, default=func.now())
updated_at = Column(TIMESTAMP, nullable=False, default=func.now(), onupdate=func.now())
e.迁移模型
安装依赖
pip install alembic
创建迁移仓库
alembic的使用类似git,也可以进行版本回退,并都需要先创建好一个迁移仓库。在项目根目录下,使用以下命令生成仓库:
alembic init alembic # init后面的是目录名称,也常为migrations
修改env.py
from src.app.core.database import Base
from src.app.core.config import settings
# 导入编写的数据模型(如果不导入,执行迁移脚本后数据库只有版本表,没有数据模型表)
from src.app.modules.persons.models import Person
from src.app.modules.users.models import User
from src.app.modules.records.models import Record
# 添加
config.set_main_option("sqlalchemy.url", settings.DATABASE_URL)
# 修改
target_metadata = Base.metadata
生成迁移脚本
alembic revision --autogenerate -m "修改的内容,如:add user table"
执行迁移脚本
生成迁移脚本后模型并不会迁移到数据库,还需执行迁移脚本
alembic upgrade head
这条命令会将数据库升级到最新的版本(head 指向最新的迁移脚本)。
降级数据库,这条命令会将数据库降级一个版本。
alembic downgrade -1
10.3 alembic
a.Alembic 是什么?
Alembic 是一个轻量级的数据库迁移工具,由 SQLAlchemy 的作者 Michael Bayer 开发。它主要与 SQLAlchemy ORM 配合使用
核心功能是:对数据库 schema(模式)进行版本控制。
你可以把它想象成软件开发中的 Git,但 Git 管理的是代码的版本,而 Alembic 管理的是数据库结构的版本。
b.为什么需要 Alembic?
在没有数据库迁移工具的情况下,团队协作和项目部署时会遇到很多麻烦:
- 开发协作困难:
- 开发者 A 在本地数据库添加了一个新表或新字段。
- 开发者 B 拉取了 A 的代码后,因为数据库结构不同,程序无法运行。
- 每个人都需要手动执行 SQL 脚本来同步数据库,极易出错和遗漏。
- 部署和升级风险高:
- 在生产环境部署新版本时,如何准确地让生产数据库的 schema 与代码要求的 schema 保持一致?
- 回滚时,如何将数据库结构退回到上一个版本?
- 缺乏历史追踪:
- 数据库结构是如何一步步变成现在这个样子的?谁在什么时候添加了哪个字段?没有清晰的记录。
Alembic 完美地解决了这些问题,它通过创建“迁移脚本”来记录数据库的每一次结构变更,使得这些变更加以版本控制、可重复、可逆。
c.核心概念
- 迁移脚本(Migration Script):
- 这是 Alembic 的核心。每个脚本都是一个 Python 文件,描述了如何将数据库从上一个版本升级到当前版本(
upgrade),以及如何回退到上一个版本(downgrade)。 - 脚本中包含了使用 Alembic API 执行的操作,如
create_table,add_column,alter_column等。
- 这是 Alembic 的核心。每个脚本都是一个 Python 文件,描述了如何将数据库从上一个版本升级到当前版本(
- 迁移环境(Migration Environment):
- 这是一个包含
alembic.ini配置文件和env.py脚本的目录。 alembic.ini: 存放基础配置,如数据库连接字符串。env.py: 迁移脚本运行的“运行时环境”,每次执行 Alembic 命令时都会加载它。在这里你可以设置数据库连接、读取模型元数据等。
- 这是一个包含
- 版本历史(Version History):
- Alembic 会在你的数据库中创建一个名为
alembic_version的特殊表。这个表只有一列,记录着当前数据库所处在的迁移版本号。 - 通过对比这个表中的版本号和本地的迁移脚本,Alembic 就知道哪些升级或降级需要执行。
- Alembic 会在你的数据库中创建一个名为
10.4 基础的增删改查操作
在开始 CRUD 之前,需要先理解几个核心概念:
- 模型(Model):继承自
declarative_base()的类,对应数据库中的一张表。 - 会话(Session):与数据库交互的主要入口,负责管理所有持久化对象。
- 事务(Transaction):通过 Session 管理,在
session.commit()时提交所有更改。
a. 增加(Create)
操作:向数据库中添加新记录。
方法:
session.add(instance): 添加单个对象session.add_all([instance1, instance2]): 添加多个对象session.commit(): 提交事务,将数据真正写入数据库
示例:
# 创建新用户对象
new_user = User(name="张三", age=25)
# 添加到 session
session.add(new_user)
# 提交到数据库
session.commit()
print(f"新增用户ID: {new_user.id}") # 提交后会自动填充自增的 ID
# 批量添加
user_list = [
User(name="李四", age=30),
User(name="王五", age=28),
User(name="赵六", age=35)
]
session.add_all(user_list)
session.commit()
b. 查询(Read)
最常用的操作,SQLAlchemy 提供了丰富的查询方式。
基本查询方法:
# 查询所有用户
all_users = session.query(User).all()
print("所有用户:", all_users)
# 查询第一个用户
first_user = session.query(User).first()
print("第一个用户:", first_user)
# 根据主键查询
user_by_id = session.query(User).get(1) # 查询 id=1 的用户
print("ID为1的用户:", user_by_id)
# 查询数量
user_count = session.query(User).count()
print(f"用户总数: {user_count}")
过滤查询:
from sqlalchemy import or_
# WHERE 条件查询
users_30 = session.query(User).filter(User.age == 30).all()
print("年龄为30的用户:", users_30)
# WHERE 多条件查询
user = db.query(User).filter(User.age == 20, User.height == 180).first()
# 多种过滤方式
users_25_30 = session.query(User).filter(User.age > 25, User.age < 30).all()
print("年龄在25-30之间的用户:", users_25_30)
# 或者使用 filter_by (更简洁,但只能用于等值比较)
users_30_alt = session.query(User).filter_by(age=30).all()
# OR 条件
users_25_or_35 = session.query(User).filter(or_(User.age == 25, User.age == 35)).all()
print("年龄25或35的用户:", users_25_or_35)
# LIKE 查询
users_li = session.query(User).filter(User.name.like('张%')).all()
print("姓张的用户:", users_li)
排序和限制:
# 按年龄升序排序
users_asc = session.query(User).order_by(User.age).all()
print("按年龄升序:", users_asc)
# 按年龄降序排序
users_desc = session.query(User).order_by(User.age.desc()).all()
print("按年龄降序:", users_desc)
# 限制返回数量
first_two_users = session.query(User).limit(2).all()
print("前两个用户:", first_two_users)
# 分页查询 (offset + limit)
page_size = 2
page_number = 1
users_page = session.query(User).offset(page_size * (page_number - 1)).limit(page_size).all()
print(f"第{page_number}页用户:", users_page)
desc() 函数 vs .desc() 方法
desc()函数(推荐)
from sqlalchemy import desc
# 可以接受字符串
query.order_by(desc("age"))
# 也可以接受列对象
query.order_by(desc(User.age))
# 甚至接受表达式
query.order_by(desc(User.age + User.bonus))
.desc()方法
# 只能在列对象上调用
query.order_by(User.age.desc())
# 不能在字符串上调用
query.order_by("age".desc()) # 错误!字符串没有.desc()方法
两种用法的对比
| 特性 | desc() 函数 |
.desc() 方法 |
|---|---|---|
| 字符串参数 | ✅ desc("age") |
❌ "age".desc() |
| 列对象参数 | ✅ desc(User.age) |
✅ User.age.desc() |
| 表达式参数 | ✅ desc(User.age + 10) |
✅ (User.age + 10).desc() |
| 可读性 | 明确排序方向 | 更面向对象 |
| 使用频率 | 更常用 | 较少用 |
c. 更新(Update)
操作:修改已存在的记录。
方法:
- 先查询到对象
- 修改对象属性
- 提交会话
示例:
# 方法1:先查询再修改
user_to_update = session.query(User).filter_by(name="张三").first()
if user_to_update:
user_to_update.age = 26 # 修改属性
session.commit()
print("更新成功")
# 方法2:批量更新
session.query(User).filter(User.age < 30).update({"age": User.age + 1})
session.commit()
print("批量更新完成")
d. 删除(Delete)
操作:从数据库中删除记录。
方法:
session.delete(instance): 删除单个对象- 结合查询进行批量删除
示例:
# 方法1:先查询再删除
user_to_delete = session.query(User).filter_by(name="赵六").first()
if user_to_delete:
session.delete(user_to_delete)
session.commit()
print("删除成功")
# 方法2:批量删除
session.query(User).filter(User.age > 40).delete()
session.commit()
print("批量删除完成")
10.5 条件查询,分页
编写分页依赖函数,这个函数会接收请求url中的查询参数并返回一个字典,在需要分页查询的业务的路径操作函数中注入分页依赖函数即可获取url中的查询参数。此后根据查询参数进行数据库针对查询。
# dependencies.py
def get_query_params(
page: int = Query(1, ge=1, description="页码(从 1 开始)"),
page_size: int = Query(20, ge=1, le=100, description="每页记录数"),
sort: str = Query("created_at,desc", description="排序字段,格式为 field,asc|desc"),
keyword: Optional[str] = Query(None, max_length=128, description="根据名称进行模糊搜索")
):
"""获取人员查询参数"""
return {
"page": page,
"page_size": page_size,
"sort": sort,
"keyword": keyword
}
# router.py
from src.app.core.dependencies import get_query_params
@person.get('/persons')
def get_persons(query_params=Depends(get_query_params), db: Session = Depends(get_db)):
return service.get_persons(db, query_params)
视图函数:
# service.py
def apply_sorting(query, sort_str: str):
if not sort_str:
return query.order_by(desc(Person.created_at))
try:
sort_field, sort_order = sort_str.split(',')
if hasattr(Person, sort_field):
# 获取列对象
sort_column = getattr(Person, sort_field)
if sort_order.lower() == 'desc':
# 根据列对象进行排序
return query.order_by(desc(sort_column))
else:
return query.order_by(asc(sort_column))
except (ValueError, AttributeError):
# 如果排序格式错误或字段不存在,使用默认排序
pass
return query.order_by(desc(Person.created_at))
def get_persons(db, query_params: dict):
"""
获取人员列表
"""
# 构建基础查询
query = db.query(Person)
# 模糊查询 - 按人名搜索 .strip()表示将keyword对应的值去掉空格
if query_params.get("keyword") and query_params["keyword"].strip():
# 若存在keyword且去掉空格后仍有实质内容,则将通配符%加到值里用于模糊查询
keyword = f"%{query_params['keyword'].strip()}%"
query = query.filter(Person.name.ilike(keyword)) # ilike不区分大小写,like区分大小写
# 获取总数
count = query.count()
# 处理排序
query = apply_sorting(query, query_params.get("sort", ""))
# 分页
page = query_params.get("page", 1)
page_size = query_params.get("page_size", 20)
# 根据页码和每页条数计算偏移量
skip = (page - 1) * page_size
# 根据偏移量和每页条数进行分页查询,offset(x)表示跳过前x条数据,limit(x)表示只查询x条数据
# 例如进行模糊查询后拿到了20条数据,offset(10).limit(5)获取到的是11~15的5条数据,这就表示查询的是第三页数据,每页5条
persons = query.offset(skip).limit(page_size).all()
# 转换为响应模型
results = []
for person in persons:
results.append({
"personId": person.person_id,
"name": person.name,
"gender": person.gender,
"age": person.age,
"isSelf": person.is_self
})
# 返回完整的响应对象
return {
"count": count,
"results": results
}
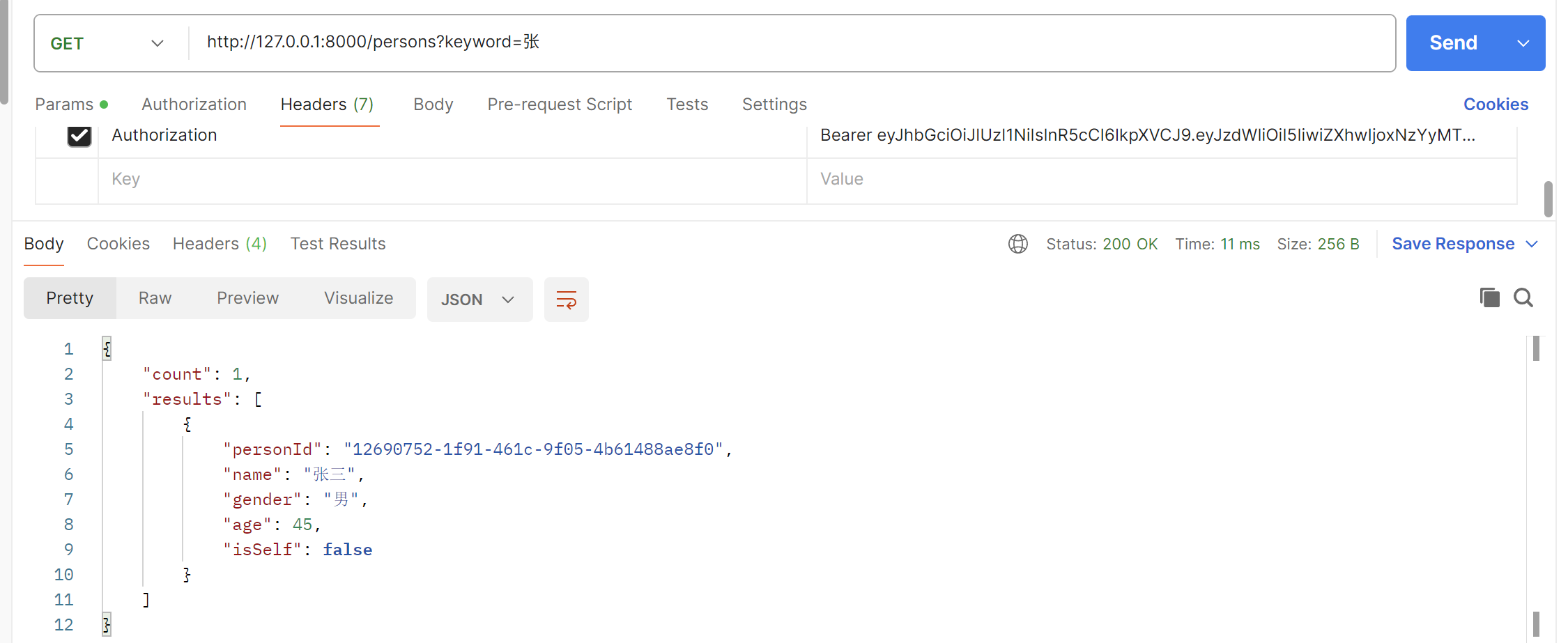
a.根据关键词模糊查询
| 场景 | 写法 | 对应 SQL |
|---|---|---|
| 以关键字开头 | User.name.like('张%') |
WHERE name LIKE '张%' |
| 以关键字结尾 | User.name.like('%张') |
WHERE name LIKE '%张' |
| 包含关键字 | User.name.like('%张%') |
WHERE name LIKE '%张%' |
| 单个字符匹配 | User.name.like('张_') |
WHERE name LIKE '张_' |
b.根据页码与每页显示数进行分页查询
不分页的总数据
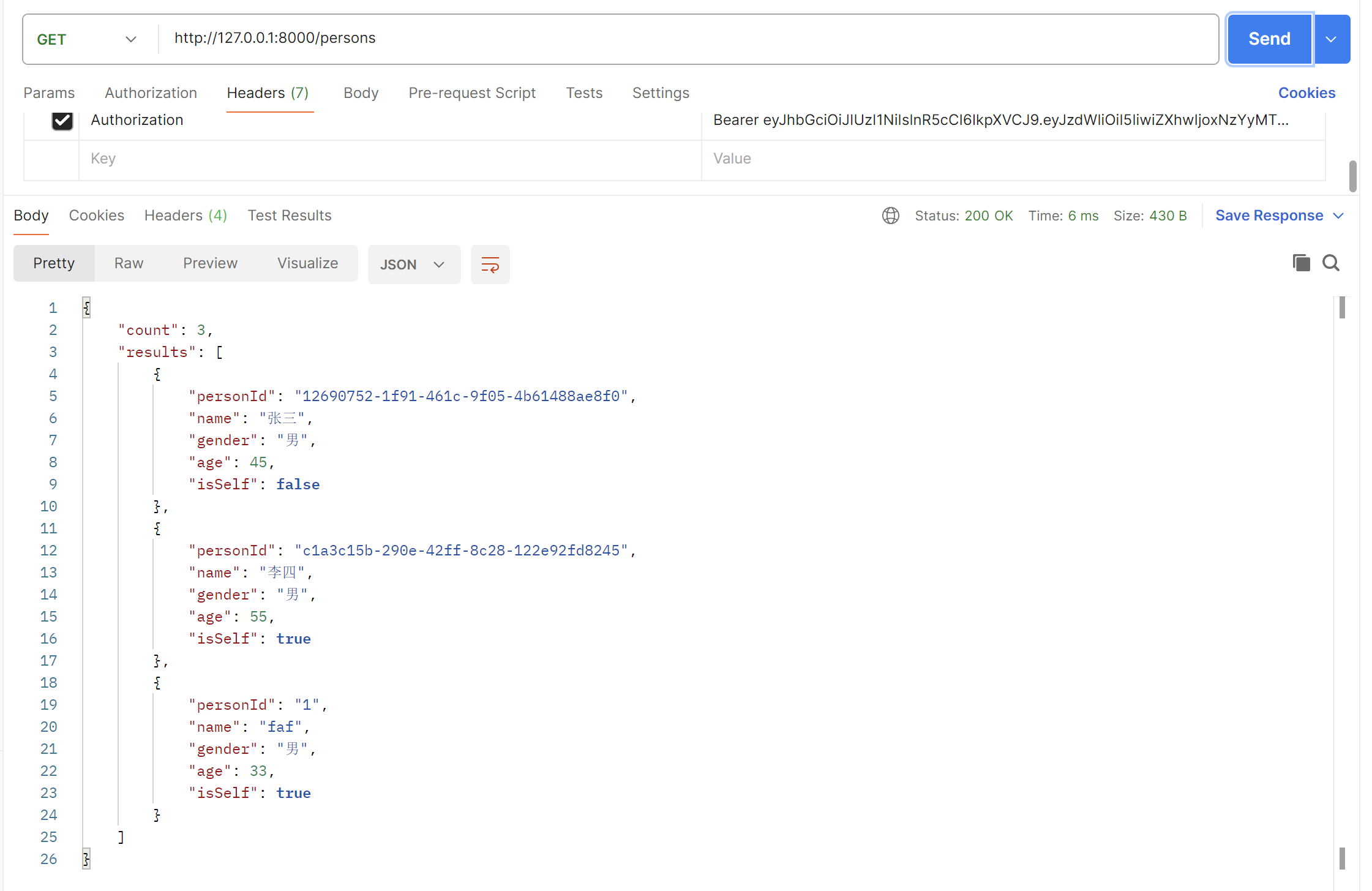
每页一条数据,第二页
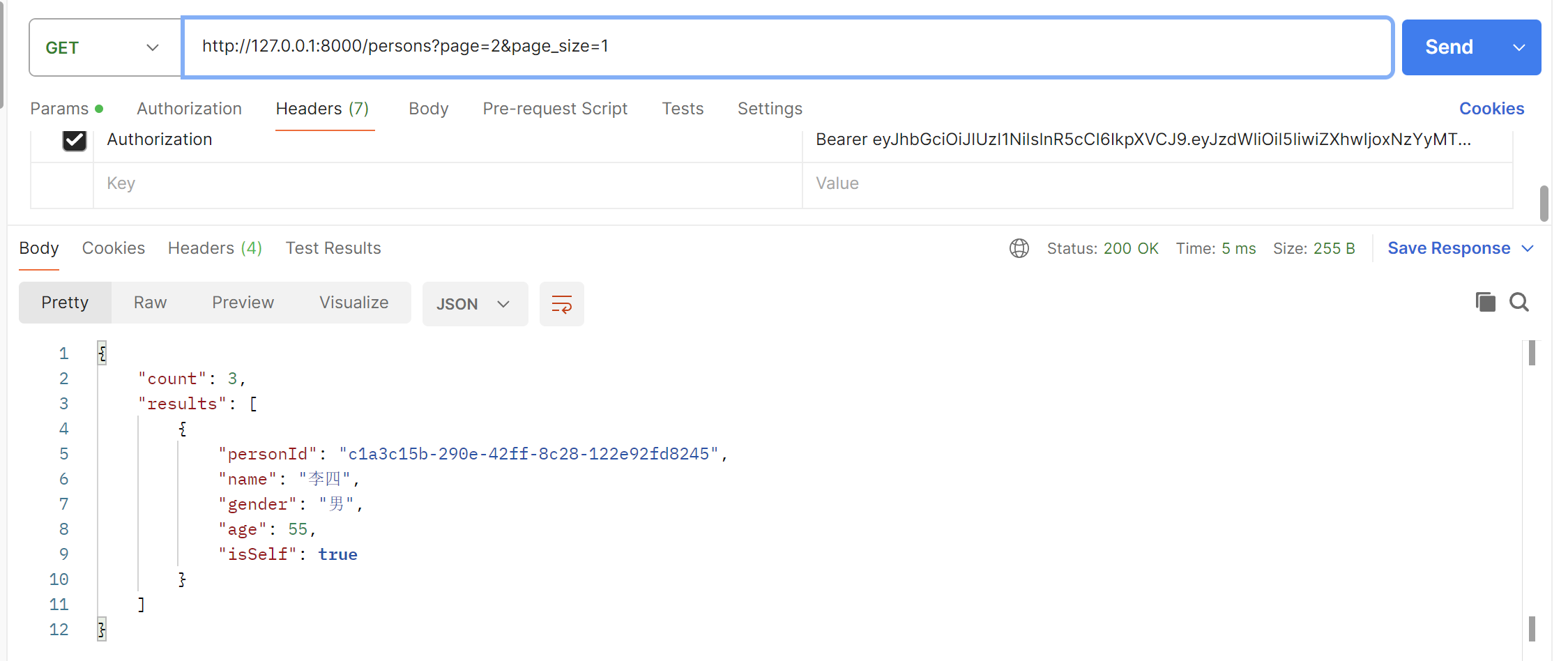
评论区 2